Concept & Storyboard Testing
Validate a script or storyboard before it hits production. Surface confusion, brand-fit issues, and emotional pull at the cheapest stage to fix them.
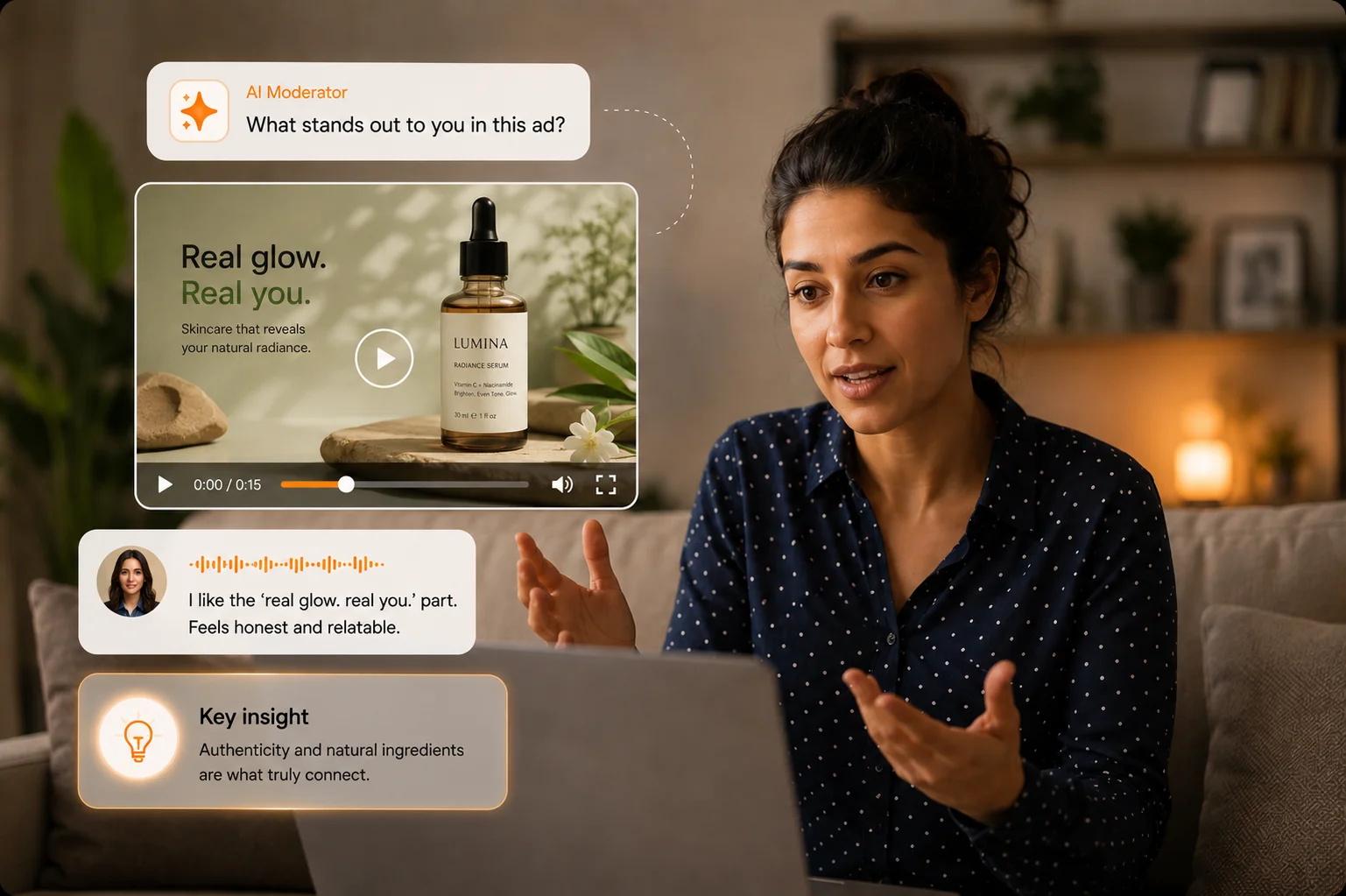
Traditional ad testing delivers scores without explanations. Alchemic's AI-moderated interviews reveal what resonates and why, before you commit your media budget.

[The Problem]
Traditional research makes you choose: quick feedback from surveys, or deep insights from a handful of focus groups.
Either way, you're making creative decisions with incomplete information. Critical questions remain unanswered:
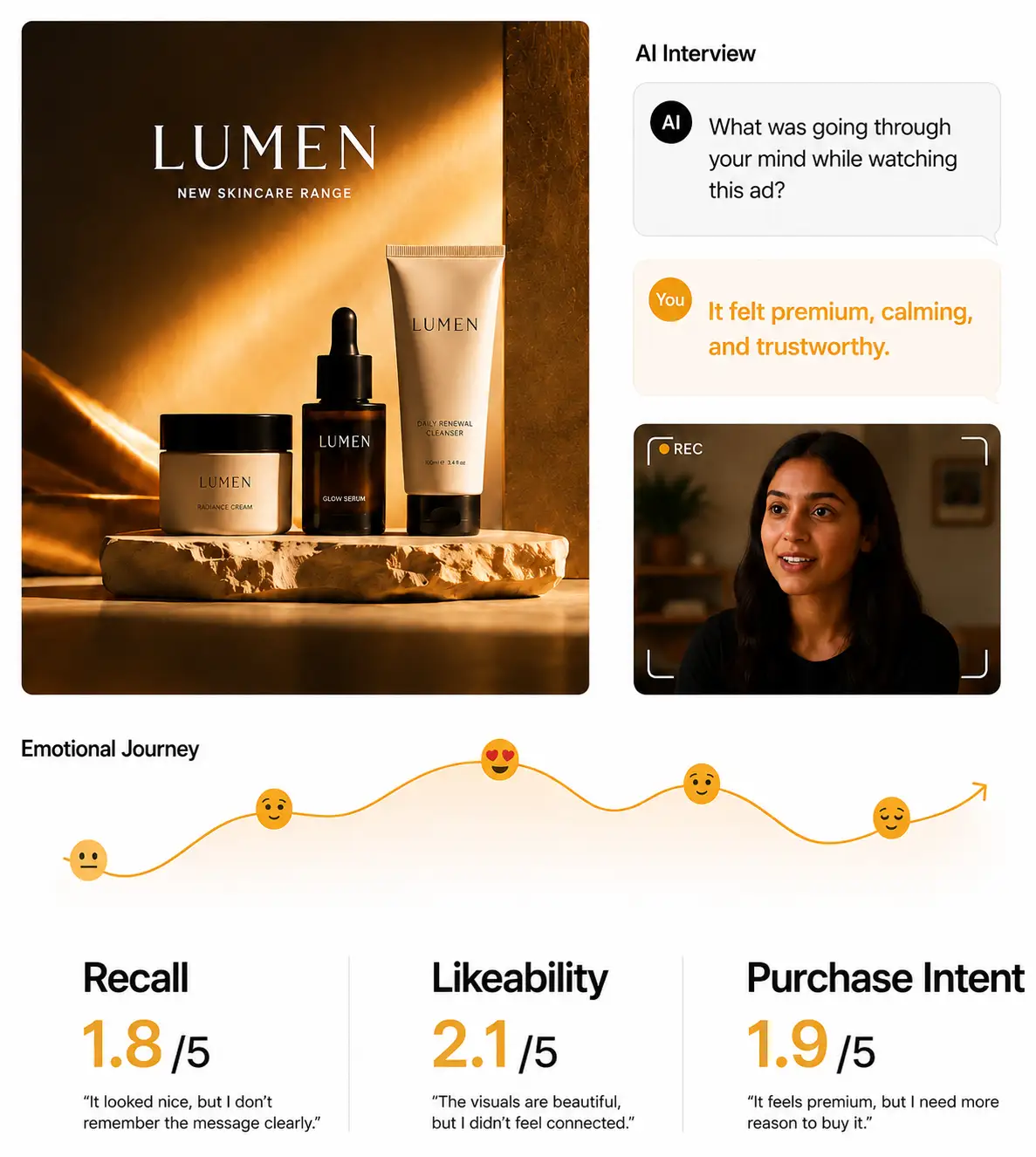
[The Solution]
AI-moderated interviews with hundreds of consumers. Discover what resonates, what falls flat, and exactly why. Mixed methods research at the scale and speed your timeline demands.
Camera-on, AI-moderated. Goes beyond the script to probe — and reads facial emotion as respondents react. Conversational depth surveys can’t capture, paired with non-verbal cues focus groups miss.
Hundreds of concurrent interviews. 57+ languages. Statistical confidence with qualitative depth.
AI generates consultancy-grade reports with key themes, summaries, and consumer verbatim quotes.
[How It Works]
Upload creative assets and ad testing objectives. Our expert human researchers tailor the AI to your specific study.
AI moderator shows concepts and conducts adaptive interviews. Probes reactions to specific elements and explores unexpected responses.
AI synthesizes patterns: which elements resonate, where messaging confuses, what drives preference. Strategic reports with explanatory verbatims.
[Use Cases]
Whatever stage your creative is at — script, animatic, final cut, or already running — you can test it the same week.
Validate a script or storyboard before it hits production. Surface confusion, brand-fit issues, and emotional pull at the cheapest stage to fix them.
Test rough-cut creative before final post. Catch pacing, music, and final-frame branding issues while the edit is still flexible.
Pressure-test a finished spot before media commit. Confirm the message lands across segments, languages, and devices.
Run multiple creative cuts in parallel, scaling from 2 variants to 10+ — between-subjects design with rotated exposure, no order bias. Camera-on viewing captures emotion as it happens; you see which version drives recall, which drives intent, and the moment each spot wins or loses.
Field a wave 2–4 weeks after launch. Measure recall lift, message takeaway, and brand-association shift vs your launch baseline.
Test the same creative across markets in 57+ languages — natively moderated in each, including native-Arabic for Gulf markets. Catch what plays in Mumbai but falls flat in Riyadh before you spend on adaptation.
[Methodology]
A 30-second spot is short. Most ad tests miss the part where consumers process it — and miss why they did or didn't react. Alchemic's AI moderator runs a five-stage probe on every interview.
Before any specific question, the AI asks what stayed with the respondent a minute after watching. Unprompted recall is the cleanest signal of which elements actually landed.
The AI then probes specific creative elements — the opening shot, the music, the final-frame brand callout, the call-to-action — one at a time. Each element gets its own emotional read.
Camera-on interviews capture facial emotion across the spot — joy, surprise, confusion, disgust, calm, sadness, anger, fear — on a per-second timeline. Strong-emotion moments are auto-flagged so you see exactly when the ad lands or loses the viewer.
A separate prompt later in the interview asks which brand the spot was for — without showing the creative again. Brand confusion shows up here, not in scorecards.
The AI closes with a relevance question: “What change, if any, would make this ad more relevant to someone like you?” Diagnostic, not prescriptive — keeps the read on consumer fit, not creative direction.
[Deliverables]
Live reports, not 60-page PDFs delivered six weeks late. Every output is queryable, exportable, and built to defend the recommendation in a board meeting.
Themes auto-extracted from every interview, organised in an L1 → L2 → L3 hierarchy. Drill from a top theme into the underlying respondents, into the exact verbatim quote, into the exact moment in the video.
Every quote tagged by theme, sentiment, segment, and respondent profile. Export the relevant ones to your deck in two clicks.
Per-element scores plus the why: which element drove emotional response, which confused, which got remembered, which got ignored.
How emotion shifted across the spot — second by second for video, region by region for static (heat-map style). Pinpoints the exact moment a creative gains or loses the viewer, layered with the 8-emotion timeline from emotion AI.
Pivot the analysis by audience: age, geography, prior-brand user vs non-user, language, channel preference. Same study, twelve cuts.
Strong-emotion moments from every interview, auto-clipped and tagged by emotion (joy spike, confusion peak, surprise reaction). Drillable to the exact respondent and the exact second. Each reel embeds the original video and the transcript.
[The Comparison]
Traditional ad testing makes you pick: speed (forced-exposure surveys) or depth (focus groups). Alchemic delivers both.
| Forced-Exposure Survey | Focus Group | Alchemic | |
|---|---|---|---|
| Turnaround | 2–4 weeks | 3–6 weeks | Days to a week |
| Interviews | Hundreds (fixed questions) | 6–30 respondents | 200–500 adaptive interviews |
| Languages | Available, typically translated post-hoc | Available, typically translated post-hoc | 50+ natively |
| Insight depth | Scores only | Discussion notes | Scores + the conversational why |
| Element-level diagnosis | None | Partial, moderator-led | Per-element AI probe |
| Creative variants | Typically 1–6 monadic variants | One or two concepts | 2 to 10+ variants |
| Brand-recall check | Prompted only | Moderator-led | Unprompted + independent verification |
| Output | Scorecard | Top-line + full report + transcripts + video | Live themed report + verbatim bank |
| Emotion AI | None | Moderator observation only | Per-second 8-emotion timeline on every respondent |
Need voice-first reach where chat doesn’t fit — DTH, regulated categories, lower-literacy markets? AI Phone Research →
Trusted by brand and insights teams at
“Alchemic is ridiculously fast, and getting both qual and quant insights at that speed is a game-changer.”
[Testimonials]
Traditional ad testing fields a fixed-question survey or runs a focus group. Alchemic’s AI moderator conducts an adaptive interview with each respondent on camera-on video — probing reactions to specific elements, following hesitation, and capturing facial emotion as it happens. You get hundreds of full interviews in days, not 60-respondent scorecards in weeks.
Video spots (15s to 90s), animatics and rough cuts, scripts and storyboards, static creative (print, OOH, social), audio (podcast pre-rolls, radio, voice ads), and multi-asset campaign concepts. Test pre-launch, post-launch, or anywhere in between.
Typical studies run 200–500 full interviews per market. Sample size scales with the number of variants you’re testing and the granularity of the segment cuts you need.
Typical timeline: brief on Day 1, fielding live within 48 hours, full report ready within a week. Faster turnarounds are possible for hot creative — fielded in a day, reported the next.
Yes. Alchemic’s interviews are video-first — camera-on with explicit respondent consent. Our emotion AI processes the recording to track 8 emotional states per second (calm, happy, surprised, sad, angry, confused, disgusted, fearful). Strong-emotion moments are auto-clipped, tagged, and surfaced in the report. You see where the ad worked, not just whether it did.
57+ languages, with native moderation in each — not translation. Tier-1 metros, Tier-2 and Tier-3 markets in India, and major emerging-market regions globally. WhatsApp distribution reaches respondents who don’t reliably show up to web surveys.
Every interview is tagged with structured response flags (speeding, straightlining, copy-pasting, low genuineness, off-brief responses). Auto-reject rules filter out poor-quality responses before they hit your report; auto-approve rules speed up clean ones. You can tune both.
Use Kantar Link or Millward Brown when you need their normative benchmark database. Use Alchemic when you need diagnostic depth on a specific creative — element-level reactions, emotion AI tracks, and real verbatim explanations of every score. Faster, deeper, multi-language by default. Many teams run both.
Every respondent gives explicit consent to camera recording before the interview begins. Recordings are stored securely, with optional face-blur anonymisation for sensitive use cases. Compliant with India DPDP, GDPR, and standard panel/consent frameworks. Full data-handling detail at /security.
Ad testing is the practice of evaluating creative — TV spots, digital videos, print, OOH — with real consumers before or after launch to understand how it lands. It covers comprehension, emotional response, brand recall, and purchase intent. Good ad testing tells you not just whether people liked the ad, but why it worked or didn't — the reasoning that drives whether you spend media behind it.
An ad is working when it gets noticed, understood, attributed to your brand, and shifts how people feel or intend to act. Quantitative scores (recall, intent) tell you the what; qualitative reactions tell you the why. The strongest signal is when consumers can play back the core message unprompted and connect it to your brand — without that, awareness rarely converts into behaviour.
Pre-launch testing happens before media spend to catch issues — confusion, weak branding, off-tone messaging — when you can still fix them. Post-launch testing measures what the ad actually did in market: recall, attribution, brand lift, behaviour change. Pre-launch saves you from spending behind a weak ad; post-launch tells you what to learn from for the next one. Most mature marketers do both.
For qualitative ad testing, 20–40 respondents per segment is usually enough to surface consistent themes — confusion points, emotional reactions, branding gaps. For quantitative norms (recall, intent benchmarks), you typically need 150–300 per cell. The right number depends on how many audiences and variants you're testing. Adding respondents past the saturation point gives diminishing returns; better to test more cells than over-sample one.
The metrics that matter most are branded attention, message comprehension, emotional response, and behavioural intent — in roughly that order. An ad that's noticed but not attributed to your brand is wasted spend. One that's understood but emotionally flat rarely shifts behaviour. Pair these with open-ended qualitative reactions to understand the reasoning behind the scores; numbers alone won't tell you what to change in the edit.
AI moderators can run the bulk of ad-testing conversations at much larger scale and faster turnaround than traditional focus groups, while preserving the depth of one-on-one interviews. Platforms like Alchemic conduct moderated conversations with hundreds of respondents in parallel, probing reactions and surfacing themes. Human moderators still matter for highly sensitive categories or exploratory work, but for most ad testing, AI-moderated qualitative research is now the default.
AI-moderated ad testing typically takes days; traditional focus-group-based testing takes weeks. Timing depends on recruitment difficulty, number of markets, and depth of analysis required, but the bottleneck has shifted. With asynchronous interviews on WhatsApp or web, respondents complete on their own time and themes are synthesised automatically — meaning you can test, learn, refine, and retest within a single campaign sprint rather than across quarters.
Yes — test each market and language separately whenever the ad will run in more than one. Cultural context, idioms, humour, and category norms shift how creative is read, and a message that lands in one market can fall flat or backfire in another. Translating verbatim isn't enough; you need native-language conversations with local consumers. Run parallel cells per market rather than averaging across them, then compare reactions side by side.